The massive change in how software is produced
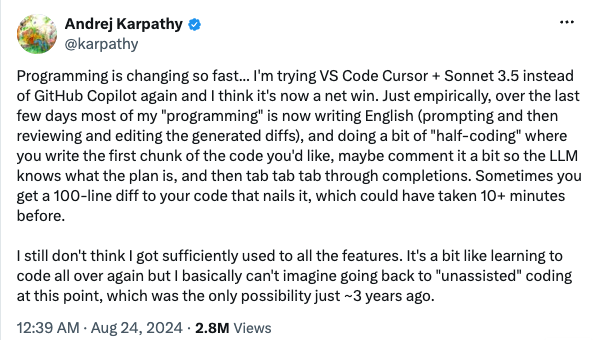
A couple of years ago, "AI in coding" mostly meant autocomplete: a tool that finished your sentence as you typed, like predictive text for programmers. It was useful, but modest. The human did the engineering while the machine saved keystrokes, as AI researcher Andrej Karpathy described in a famous X post, coding became "tab tab tab" (the keyboard shortcut to accept autocomplete suggestions).
That description is now badly out of date. Today's coding tools can read a written request, work across many files at once, run the resulting program, read the error messages, write tests (small automated checks that confirm the software behaves as intended), fix what failed, and repeat the cycle until the software works. The technical community calls these systems coding agents, because they are AI agents (i.e. software that uses AI to take actions toward a goal as opposed to simply offering suggestions) and are given the task of developing code.
The last wave of AI-assisted coding helped people write code more quickly, and it lasted a really short time. The current wave is already taking on the surrounding process, including interpreting requirements, building, checking, debugging and iterating. This changes dramatically how software gets made, governed, and trusted.
Tracing the change
The progression has been fast and incremental, which is partly why it has been easy to miss for many outsiders. It runs roughly like this: from autocomplete, to richer code suggestions, to chat-based "pair programming" (describing a problem to the AI and discussing solutions in plain language), to tools that can edit many files at once, to agents that can plan and carry out a multi-step task, to systems that participate in something close to a full development workflow.
The last two steps happened largely in the past twelve to eighteen months. In May 2025, GitHub — the world's main platform for hosting and collaborating on code — introduced a coding agent for its Copilot tool that you can assign a task to, and which returns its work as a pull request: a proposed set of code changes packaged for a human to review before they are accepted. OpenAI's Codex agent, launched the same month, runs each task inside its own isolated cloud environment (a sandbox — a walled-off space where code can run without touching real systems) and can work on several tasks in parallel while a person supervises. Anthropic, meanwhile, had released Claude Code in February 2025, a tool that can "search and read code, edit files, write and run tests, and commit and push code" largely on its own. In November 2025 after the release of Claude Opus 4.5, software developers found that Claude Code could fairly reliably, semi-autonomously build software systems suitable for production use (i.e. that could be relied on for real world use). Tools such as Cursor, Replit's Agent, Lovable and Devin are all different flavours of the same capability, and all their makers are seeing unprecedented growth in their recurring user base. The common thread is that the human increasingly delegates a task and reviews a result, instead of authoring or overseeing each line.
The change in raw capability has been measured. SWE-bench Verified is an independent test that asks AI models to fix 500 real, human-checked problems drawn from genuine open-source software projects, the kind of issues professional engineers address every day. (A benchmark is simply a standardised test used to compare systems on the same task.) In mid-2024, the best models resolved about a third of these problems. Two years later, the strongest models resolve roughly 95%.
A caveat matters here: benchmark scores are not the same as real-world reliability, and a clearly-described problem on a curated test is easier than an ambiguous request inside a sprawling, undocumented system. The exact numbers also can vary with the testing setup, so they are best read as a trend rather than a precise measure of reality. But the direction of travel is unambiguous.
Writing code isn't the same as engineering software
It is tempting to summarise all of this as "AI can write better code now." That phrase is true, but it undersells what is happening because writing code is not the same as building software.
Writing code is like drafting a paragraph. Building software is like developing, publishing and maintaining a legal, operational, or public-service system that thousands of people depend on. A paragraph can be brilliant in isolation. A public system has to be secure, accessible, performant under load, compliant with rules, observable when it breaks, maintainable by people who did not write it, and accountable to someone when it fails. Production software is the paragraph plus all of that.
The strategically important change is that AI can now produce the paragraph and begins to participate in the surrounding work: generating and running tests, checking edge cases, improving how much of the code is automatically tested, reading documentation, refactoring (tidying and restructuring existing code without changing what it does), and helping engineers understand systems too large for any one person to hold in their head.
From "vibes" to production: a crucial distinction
Much of the public excitement is really about what is sometimes called "vibe coding" (a term also coined by Andrej Karpathy): describing what you want and quickly getting something that appears to work. This is genuinely valuable for prototypes, demos, internal tools, experiments, and personal projects. Product managers, who used to face engineering and design bottlenecks in their workflows, are particularly excited to test and create prototypes without engineering support. It shortens the distance between an idea and a working sketch, and increases the speed of iterations with high-fidelity feedback from users. (It is also still a minority of professional practice: in Stack Overflow's 2025 survey, nearly 77% of developers said vibe coding is not part of their professional work.)
But "appears to work" is an intentional choice of words here. A vibe-coded prototype may not be secure, maintainable, well-tested, scalable, or compliant. Though some commercial solutions like Replit and Lovable already address large parts of that gap, there remains a considerable difference between a convincing, and often usable, demo and production-grade software. The difference is even more acute in large enterprises and regulated sectors.
The more consequential development is that AI is starting to help with the production side too: not just generating something plausible, but interpreting a specification, setting up a project's structure, implementing it across files, writing tests, debugging failures, checking usability, and preparing documentation. It does not do all of this completely reliably or unsupervised, but it increasingly participates across the lifecycle. For smaller or lower-risk projects like building a simple website, AI could already take care of everything with little to no supervision.
A squeezing lifecycle changes expectations
When a single tool can move quickly from requirement to draft implementation to tested change, the traditional stages of software work — design, build, test, iterate, document, prepare for release, code reviews — start to condense into a much shorter loop.
That contraction changes organisational behaviour. When teams can produce more, they are expected to work more. There are more experiments, more prototypes, faster iteration, and more pressure on the review and assurance functions that have to keep up. The engineer's role evolves accordingly: less time as a line-by-line author, more time as a reviewer, architect, tester, and product decision-maker who judges what the machine produced. Notably, not all developers read this as redundancy. In the same Stack Overflow survey, 64% still did not see AI as a threat to their jobs, though that was down from 68% a year earlier.
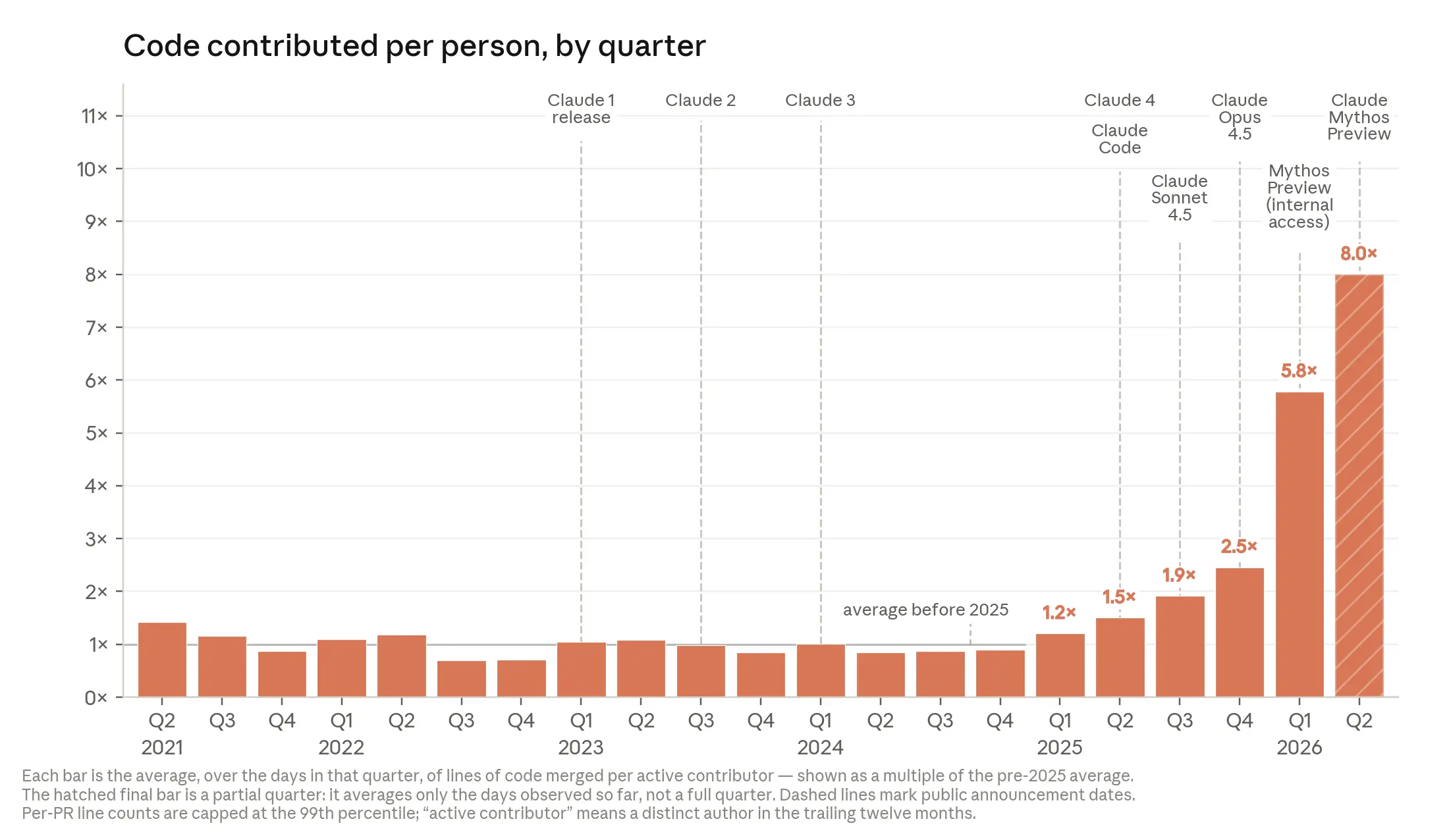
Anthropic has stated that more than 80% of the code merged into its own production systems in a recent month was written by its model; some firms claim humans no longer write code manually at all. These are self-reported, come from companies with an obvious interest in the narrative, and describe unusually AI-native environments, so we read them as an indication of where the frontier is pointing towards. The capability of coding agents in performing human-like software engineering tasks is rising rapidly with METR finding that the expert-equivalent duration of software tasks AI can handle has been doubling roughly every seven months (and the Anthropic statement linked above says four months).
A leader inside one of those AI-native environments offers a complementary view. Fiona Fung, who leads the teams behind Claude Code and Claude Cowork at Anthropic, said on Lenny's Podcast that the company's engineers now ship roughly eight times as much code per quarter as they did in 2025. The same caveats apply because this, again, is self-reported, comes from a company with an interest in the story, and counts throughput rather than quality, but it points the same way as the benchmarks: the volume of change a single engineer can set in motion has risen dramatically.
While some experimental evidence suggests that humans outperform AI in certain code-related tasks, this research predates the latest generation of coding agents and may no longer apply. A 2025 randomised controlled trial by METR found that experienced open-source developers using early-2025 AI tools on their own familiar code turned out to be 19% slower, even though they believed they were faster. Speed in a prototype, issue fix, or new feature does not guarantee speed in real, complex, well-understood systems.
I want to offer a few concrete illustrations as personal observations in lieu of universal evidence.
After six months of working with these tools, I recently used Claude Code, powered by Fable 5 (just on time before the US government blocked its access to foreigners), to finish a feature I had been putting off for a long time because earlier models had consistently struggled to build it properly. The app in question is one I built for my wife; it handles sensitive health data, and the architecture it requires is not trivial. To store certain data locally on the device, encrypt other data before it ever leaves, and meet GDPR obligations while still allowing her to share selectively with a health advisor are those layered, compliance-sensitive builds that a regulated organisation would recognise. That new, complex feature was completed and rolled out in about an hour and a half.
A seasoned software engineer we recently hosted at Gradient Gatherings, Marcio Sete, measured and described a more acute version of the transformation his job went through in the past year: work that once took sixty days and a team in a large institution can, in an AI-native setup, ship in 24 hours.
A friend of mine used to work at a large bank as a software engineering analyst until last November. He used to contribute to a feature that would take 6 months to be live in production for an internal code base. Now he works in a young scaleup, on a government contract. He is "forward deployed" (new Silicon Valley lingo for engineers working on the client’s premises) with a small team and releases one feature a day for an external software system, for a government client. He also says he is working far more than he used to. The ceiling on what one person can attempt has lifted, and so have the hours.
These anecdotes of emerging practice are aligned with what the benchmarks and company claims suggest. There is a cost here that the throughput figures do not capture. The same change that lets one person do the work of a team can be isolating. Fung describes how, once nearly everyone on her team was working through their own agents, the job began to feel like "a lonely experience". So much so that they brought back shared rituals such as pairwise-programming lunches and hackathons to keep people building alongside one another. If the unit of work is becoming a single person directing a fleet of agents rather than a team writing code together, then some of what made the craft satisfying, things like the flow state, the shared breakthrough, the colleague at the next desk, countless hours debating an if-statement vs. a vector dot product, is among the first things at risk of being lost, even as output climbs. My friend's longer hours and the loneliness Fung points to may be two faces of the same problem: nobody seems to be setting boundaries that respect the natural limit on how much they take on.
What can go wrong
One emerging idea is worth considering carefully because it may reshape how teams work. When generating a working implementation becomes cheap and fast, teams can produce many candidate versions of a feature or product and then choose among them as opposed to spending time carefully designing one version up front. This approach has become known as "slot machine programming" and some Anthropic teams apparently use it.
If that pattern takes hold, more time will be devoted to the discernment of what option we should trust, maintain, and deploy. Evaluation, testing, taste and judgment become higher value skills. This is still an emerging possibility and not standard practice, and it should not be overstated, but it points to where organisational effort may need to concentrate.
Faster generation does not make the failure modes disappear; it makes them faster, too. Several are now well documented.
Coding agents can form sticky assumptions: an early design decision, built upon by later work, that the system then resists unwinding even when it is wrong. They can invent software components that do not exist — so-called "hallucinated APIs or libraries," where the AI confidently calls a function or service that was never built (an API, or application programming interface, is the agreed set of commands one piece of software uses to talk to another). They can produce breakable structures, store the same data in inconsistent ways, miss the context of an existing codebase, and fix bugs with great confidence while forgetting previous behaviours to preserve or even being entirely wrong. They can also be alarmingly literal: the widely-read software engineer and researcher Simon Willison recently called the Fable 5 model used for coding "relentlessly proactive" after a request merely to inspect a small visual bug led it to write its own automation code and open browsers on his machine unprompted — a vivid reminder, as he noted, that such tools are indeed impressive and should be run inside a sandbox.
Security is the most quantifiable risk. Although it is from Oct 2025 and so predates the current generation of models and coding agents, Veracode's 2025 analysis of code generated by more than a hundred models found that roughly 45% of samples contained a security vulnerability. They also found that this rate had not improved as the models got more capable, because the pressures that make models better at producing working code do not automatically make them better at producing secure code (it should be noted that the company sells products that address these problems so the work should be treated with caution). More recent AI models (including Anthropic’s Mythos) have greater capability at detecting security vulnerabilities but there is a shortage of recent independent analyses that show the security quality of AI-generated code from coding agents.
Meanwhile, developers are cautious: in Stack Overflow's 2025 survey, adoption rose to 84% (up from 76% the year before), yet the share of developers who say they do not trust AI output for accuracy climbed to 46%, up from 31%. I look forward to seeing the results of Stack Overflow’s 2026 Developer Survey which is underway as I write to see if the latest generation of coding agents has shifted this.
Why this matters for organisations
For companies operating in regulated industries and for the public-sector, the implications cut two ways.
On the one hand, delivery cycles that have historically run for months or years shorten dramatically. That is a real opportunity for institutions under pressure to modernise and not only that. They can also enter new markets, develop new systems and products, fix existing bugs, redesign workflows and achieve efficiencies, better services faster.
On the other, procurement, assurance, and accountability models were built for a slower world. If software can be generated quickly, the binding constraint becomes the organisation's ability to validate, secure, test, document, and stand behind it. This is the shift practitioners at the frontier describe in their own terms. Fung puts it simply: "coding is no longer the bottleneck." On a team where engineers, designers and product managers now all commit code, she frames the central open question as verification, i.e., how do you keep confidence that what ships is correct? Leaders will need to distinguish more intentionally between demo speed (i.e. how fast something convincing appears) and production readiness (i.e. whether it can be safely deployed and maintained). The two look similar in a presentation but remain worlds apart in operation.
This is where responsible AI practice and software assurance converge. Existing frameworks already offer a foundation: the US NIST Secure Software Development Framework (SP 800-218) for lifecycle controls, and the OWASP Top 10 for Large Language Model Applications for AI-specific risks. The practical task for leaders is to ensure that validation, human review, security review, audit trails, documentation, and clear lines of accountability scale with that new speed.
The key message is that faster software creation demands organisations to move assurance to occur throughout the software lifecycle, therefore leaders and accountable persons need to move closer to where software is made.
The takeaway
AI is changing the unit of work in software engineering, from writing lines of code toward specifying, generating, evaluating, and selecting working systems at an incredibly fast pace. The capability curve is steep and still climbing. But trust is low, security may not be keeping pace, and the gap between demonstrated assurance and a dependable public system remains wide.
The strategic question is therefore both how fast can we build and how well can we evaluate, govern, and trust what gets built? The organisations that answer the second question well can turn this unprecedented shift into an advantage. The ones that ignore this challenge for too long may be fueling a liability that can become very quickly too big and too unmanageable.
Company-reported productivity figures and individual practitioner anecdotes are presented as emerging-practice signals, not settled fact.
I'd like to thank Bill Simpson-Young for his feedback and support.
About the authors

Alberto Chierici
Alberto Chierici, Gradient's Principal AI Specialist, translates frontier AI research into clear, usable ideas and builds with it himself. He partners with founders scaling in the AI era to help them move fast without cutting the corners that matter.